MLRun Module
Overview
The MLRun module turns the Ecosystem.Ai Workbench2 console into a
full ML lifecycle hub: pull data from MongoDB, draft engineered
feature pipelines through a natural-language AI pipeline assistant,
train sklearn, xgboost, lightgbm, or pytorch (tabular
wrapper) models against a containerised trainer, emit the entire
lifecycle as a runnable Python project (feature pipeline, training,
scoring, K8s deploy), and deploy the trained model — alongside the
Java-based ecosystem-runtime — onto Docker Desktop Kubernetes with
two clicks.
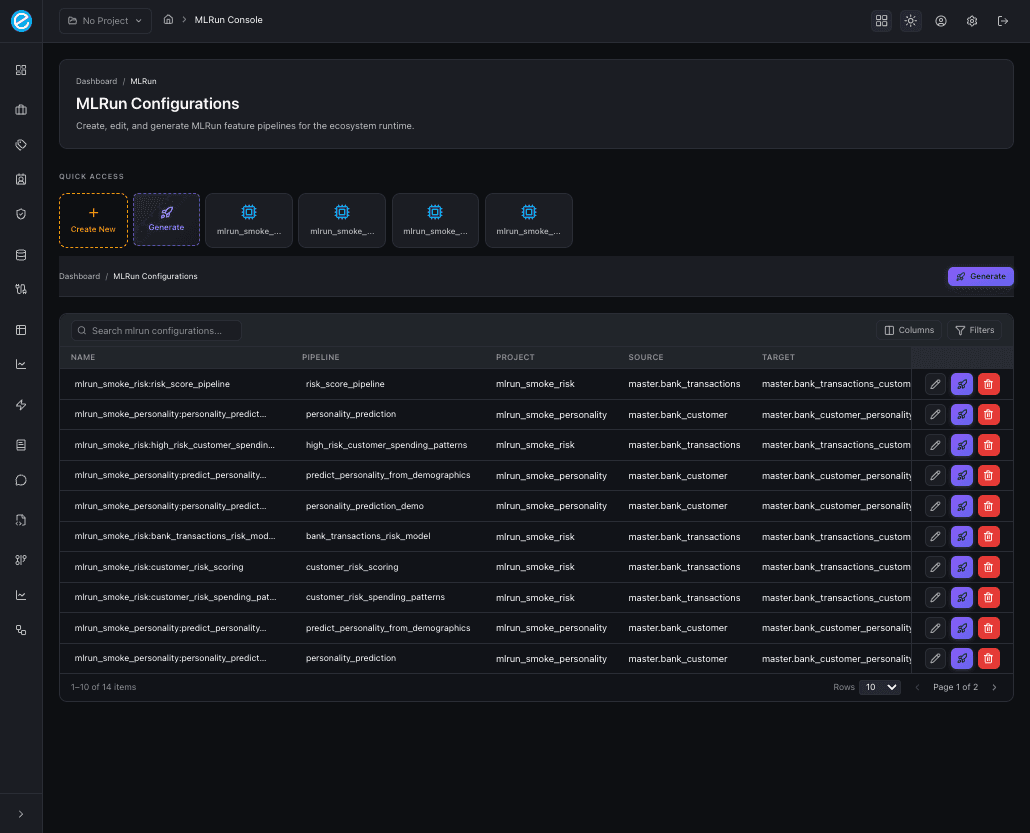
The configuration editor is a 13-tab IDE for one MLRun configuration:
Overview · Project · Data Source · Features · H2O Frame · Training · Models · Training Runs · Adapters · Python · Runs · Deployments · Generate
For a screenshot-led walkthrough of every tab see Console Tour.
Two opinionated reference use-cases ship out of the box and seed real training runs on first install:
- Customer Spend Risk — binary classification on
master.bank_transactions, demonstrating numeric + categorical feature engineering and risk scoring against anecosystem-runtimepod. - Customer Personality — multiclass classification on
master.bank_customer, predictingpersonalityfrom generic demographic fields (age, gender, income band, region, life stage).
Benefits
- Single-pane lifecycle: feature engineering, training, scoring, and deployment in one console.
- AI pipeline assistant: describe the target collection and the
prediction goal in plain English; the assistant samples the schema,
drafts the aggregation pipeline, infers the target column / problem
type, persists the configuration, and (optionally) trains every
selected framework end-to-end. Seven
pipeline_kindpresets (auto,numeric,categorical,temporal,mixed,aggregates,type_coercion) shape the generated MongoDB aggregation. - Bring-your-own framework: sklearn, xgboost, lightgbm, and a pytorch tabular wrapper using identical contracts.
- Reproducible by design: every console action is exposed in a
generated Python project (
feature_pipeline.py,train_model.py,score_model.py,deploy_to_k8s.py) so the same lifecycle can run in CI, in a notebook, or in an MLRun job. The Python tab adds toggles for training scripts, the scoring driver, and the Kubernetes deployer, so you only emit what you need. - Coexistence with MLRun CE: when MLRun Community Edition is enabled, runs land in the MLRun project store and the trainer sidecar continues to handle compute. See MLRun Community Edition.
- Runtime-native scoring: trained adapters generate
ecosystem-runtime-compatible logging payloads, so production scoring goes through the same audited paths as the rest of the platform. - Cascade-safe configurations: deleting a configuration removes
the linked feature pipelines, feature sets, training runs, and any
K8s deployments scoped to its
project_id, with a confirmation dialog that prints the final delete counts.
Architecture
┌──────────────────────────────┐
│ Workbench2 frontend │
│ /mlrun-console │
└──────────────┬───────────────┘
│
▼
┌──────────────────────────────┐
│ Workbench2 backend (FastAPI) │
│ /api/v1/mlrun-runtime/* │
│ /api/v1/k8s/* │
└─────┬──────────┬──────────────┘
feature pipe │ │ k8s api
▼ ▼
┌──────────────────┐ ┌────────────────────────────┐
│ MongoDB │ │ Docker Desktop Kubernetes │
│ master.* │ │ ┌──────────────┐ │
│ ecosystem_meta.* │ │ │ mlrun-trainer │ (8003) │
└──────────────────┘ │ │ sklearn / xgb │ │
│ │ lgbm / pytorch│ │
│ └──────────────┘ │
│ ┌──────────────────────┐ │
│ │ ecosystem-runtime │ (8091)
│ │ Java Spring scoring │ │
│ └──────────────────────┘ │
│ ┌──────────────────────┐ │
│ │ MLRun Community Ed. │ │
│ │ (optional, Helm) │ │
│ └──────────────────────┘ │
└────────────────────────────┘What ships in the seed
The seeder script (backend/scripts/seed_mlrun_use_cases.py) creates
one project, one feature pipeline, one feature set, one
configuration, and four training runs (sklearn / xgboost /
lightgbm / pytorch) per use-case. With both use-cases enabled you get:
| Asset | Spend Risk | Customer Personality |
|---|---|---|
| Source collection | master.bank_transactions | master.bank_customer |
| Target derivation | aggregation pipeline (frequent / declined) | $personality |
| Problem type | binary_classification (per use-case) | multiclass_classification |
| Frameworks trained | sklearn · xgboost · lightgbm · pytorch | sklearn · xgboost · lightgbm · pytorch |
| Activity log entry | SEED_MLRUN_USE_CASE | SEED_MLRUN_USE_CASE |
Where to next
- Installation
- Console Tour — visual walkthrough of every tab.
- Use-Case Definition
- Data Preparation
- Model Training
- Kubernetes Deployment
- Python & AI Generator
- MLRun Community Edition
- Access & Scoring
When the goal is purely to import already-trained mojo models from an MLFlow registry into the Java runtime, see MLFlow Integration. The MLRun module is the right choice when you also want to train models in-platform from feature-engineered MongoDB collections.