Use-Case Definition
An MLRun configuration is the top-level object in the console. It binds:
- A project (logical grouping; reused across runs and deployments).
- A feature pipeline (MongoDB aggregation that produces an engineered feature set).
- A feature set (the materialised collection used as training input).
- Training run history (sklearn / xgboost / lightgbm / pytorch results).
- Deployments (when Kubernetes is enabled).
The same shape is used for both reference use-cases; only the source collection, target derivation, and problem type differ.
Reference use-case: Customer Spend Risk
| Field | Value |
|---|---|
| Project id | spend_risk |
| Source DB | master |
| Source collection | bank_transactions |
| Output collection | bank_transactions_mlrun |
| Feature set name | spend_risk_features |
| Pipeline name | spend_risk_pipeline |
| Problem type | binary_classification |
| Target field | is_high_risk (derived from frequent declined / risky merchant categories) |
The target derivation runs as a $lookup + $group aggregation: any
customer with ≥3 declined transactions in the last 30 days, or any
transaction tagged with a high-risk merchant category (gambling,
crypto, cash_advance), is flagged.
Reference use-case: Customer Personality
| Field | Value |
|---|---|
| Project id | customer_personality |
| Source DB | master |
| Source collection | bank_customer |
| Output collection | bank_customer_mlrun |
| Feature set name | customer_personality_features |
| Pipeline name | customer_personality_pipeline |
| Problem type | multiclass_classification |
| Target field | personality |
| Demographic features | age, gender, income_band, region, life_stage, marital_status, dependents, tenure_months |
The personality target carries 4–6 distinct labels (typically
Industrious, Intentional, Experiential, Enthusiastic); the
seeder validates there are at least 2 distinct labels in the source
collection before training.
Configuration anatomy
A configuration row in ecosystem_meta.mlrun_configurations looks like:
{
"_id": "configuration_id",
"name": "Customer Spend Risk",
"project_id": "spend_risk",
"pipeline_name": "spend_risk_pipeline",
"feature_set_name": "spend_risk_features",
"source": { "database": "master", "collection": "bank_transactions" },
"destination": { "database": "master", "collection": "bank_transactions_mlrun" },
"problem_type": "binary_classification",
"target_field": "is_high_risk",
"feature_fields": ["amount", "merchant_category", "channel", "..."],
"tags": ["seed", "spend_risk"]
}Configurations are versioned but structurally immutable by project / pipeline name (a new configuration is created if you change either). Deletion is a cascade that removes the configuration row, the linked feature pipeline, the feature set, all training runs, and any K8s deployments tied to the project id; the confirmation dialog prints the final delete counts (see Access & Scoring — Deleting an MLRun configuration).
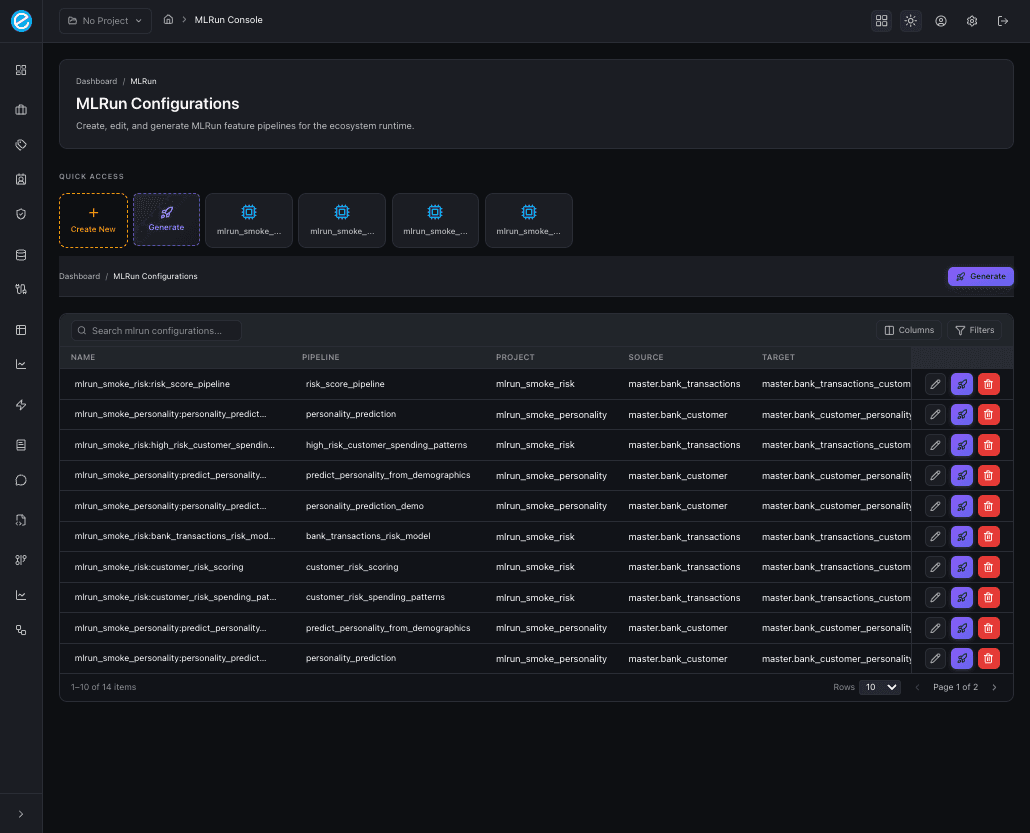
The configuration editor opens with a sticky header that shows
project_id · pipeline_name, the current state
(draft / active / archived), the version, a N/5 lifecycle
sections ready badge, and three actions (Back, Generate,
Save version). Below the header is the 13-tab strip described in
the Console Tour.